Mathematical methods
Mathematical modeling of physical processes and mathematical methods of data analysis are an integral part of modern experimental physics. There is a constant need for both improving existing methods and developing fundamentally new approaches.
Statistical regularization of incorrect inverse problems
One of the tasks solved by the group is the popularization and development of the statistical regularization method created by V.F. Turchin in the 70s of the XX century.
A typical incorrect inverse problem that arises in physics is the Fredholm equation of the first kind:
In fact, this equation describes the following: the hardware function of the device acts on the studied spectrum or other input signal , as a result, the researcher observes the output signal . The aim of the researcher is to restore the signal from the known and . It would seem that signal recovery is not a difficult task, since the Fredholm equation has an exact solution. But the Fredholm equation is incorrect - an infinitesimal change in the initial conditions leads to a final change in the solution. Thus, the presence of noise present in any experiment invalidates attempts to solve this equation for sure.
Theory
Consider a certain algebraization of the Fredholm equation:
In terms of mathematical statistics, we must evaluate using implementation , knowing the probability density for and matrix content. Acting in the spirit of decision theory, we must choose a vector function , defining on base of and called strategy. In order to determine which strategies are more optimal, we introduce the squared loss function:
where is the best decision. According to the Bayesian approach, we consider as random variable and move our uncertainty about in prior density , Expressing reliability of the various possible laws of nature and determined on the basis of information prior to the experiment. With this approach, the choice of an optimal strategy is based on minimizing posterior risk:
Then the optimal strategy in case of the square loss function is well known:
Posterior density is determined by the Bayes theorem:
In addition, this approach allows us to determine the dispersion of the resulting solution:
We got the solution by introducing a priori density . Can we say anything about the world of functions, which is defined by a priori density? If the answer to this question is no, we will have to accept all possible equally probable and return to the irregular solution. Thus, we should answer this question positively. This is the statistical regularization method - regularization of the solution by introducing additional a priori information about . If a researcher already has some a priori information (a priori density of ), he can simply calculate the integral and get an answer. If there is no such information, the following paragraph describes what minimal information a researcher can have and how to use it to obtain a regularized solution.
Prior information
As British scientists have shown, the rest of the world likes to differentiate. Moreover, if a mathematician will be asked questions about the validity of this operation, the physicist optimistically believes that the laws of nature are described by "good" functions, that is, smooth. In other words, he assigns smoother a higher a priori probability density. So let's try to introduce an a priori probability based on smoothness. To do this, we will remember that the introduction of the a priori probability is some kind of violence against the world, forcing the laws of nature to look comfortable for us. This violence should be minimized, and by introducing an a priori probability density, it is necessary that _ Shannon_'s information regarding contained in be minimal. Formalizing the above, let us derive a type of a priori density based on the smoothness of the function. For this purpose, we will search for a conditional extremum of information:
Under the following conditions:
- Condition for smoothness . Let be some matrix characterizing the smoothness of the function. Then we demand that a certain value of the smoothness functional is achieved:
The attentive reader should ask a question about the definition of . The answer to this question will be given further down the text.
- The normality of probability per unit:
Under these conditions, the following function will deliver a minimum to the function:
The parameter is associated with , but since we don't actually have information about the specific values of the smoothness functionality, it makes no sense to find out how it is associated. Then what to do with , you ask? There are three paths:
- select the value of the parameter manually, and thus proceed to regularization of Tikhonov
- average all possible , assuming all possible equally probable
- choose the most likely by its a posteriori probability density of . This approach is correct if we assume that the experimental data contains enough information about
The first case is of little interest to us. In the second case, we get the following formula for the solution:
The third case will be considered in the next section using the example of Gaussian noises in an experiment.
Gaussian noises case
The case where the errors in the experiment are Gaussian distributed is remarkable in that an analytical solution to our problem can be obtained. The solution and its error will be as follows:
where is covariance matrix of a multidimensional Gaussian distribution, is the most probable value of the parameter , which is determined from the condition of maximum a posteriori probability density:
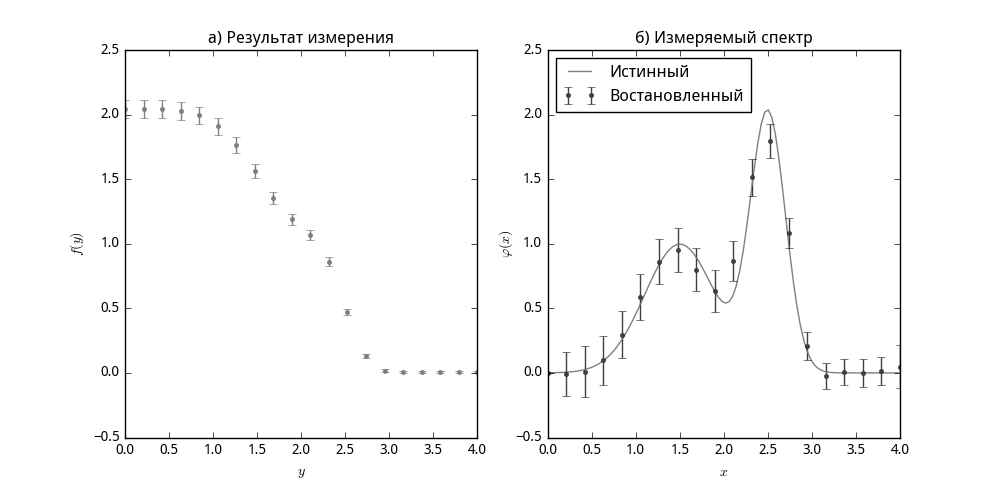
As an example, we consider the reconstruction of a spectrum consisting of two Gaussian peaks that fell under the action of an integral step kernel (Heaviside function).
Optimal experiment planning with parameter significance functions

|
This section is being finalized ... |