Table of contents
- 1 How to read this documentation
- 2 Meta-data processor
- 2.1 Meta-data object structure
- 2.2 Meta-data composition
- 2.3 Configuration
- 2.4 Hidden values
- 3 Framework
- 3.1 Context
- 3.2 Context plugins
- 3.3 Providers and navigation
- 4 Data flow
- 4.1 Push model
- 4.2 Tasks
- 5 Envelopes
- 5.1 Streaming envelope format
- 5.2 Tagless envelope format
- 5.3 Envelope description
- 6 Storage plugin
- 6.1 File storage
- 7 Control plugin
- 8 Language extensions
- 8.1 GRoovy INteractive Dataforge
- 8.2 KOtlin Dataforge EXtension
An important feature of DataForge framework is ability to work with meta-data. This documentation is automatically generated by grain script from markdown and html pieces. Such pieces are called shards. The shard consists of data in one of supported formats and meta-data header. The ordering of shards is automatically inferred from meta-data by the script.
The meta-data of each shards includes version of this precise shard last update date, it's label for reference and ordering information.
The main and the most distinguishing feature of DataForge framework is a concept of data analysis as a meta-data processor. First of all, one need to define main terms:
Data. Any information from experiment or simulation provided by user. The data format is not governed by DataForge so it could be presented in any form. The important point concerning data is that data is by default immutable. Meaning the program could create its modified copies (which is not recommended), but could not modify initial input in any way.
Meta-data. Meta-data contrary to data has a fixed internal representation provided by Meta object. Meta is simple tree-like object that can conveniently store values and Meta nodes. Meta-data is either provided by user or generated in analysis process. Inside the analysis process Meta is immutable, but for some purposes, changeable meta nodes could be used during analysis configuration and results representation (see Configuration).
The fundamental point of the whole DataForge philosophy is that every external input could be either data or meta-data. This point could seem dull at first glance, but in fact, it have a number of very important consequences:
No scripts. DataForge encourages user not to use imperative code to manipulate data. Any procedure to be performed on data should be presented either by some hard-coded meta-data processor rule (the function that takes data and metadata and produces some output without any additional external information) or as declarative process definition in form of meta-data. Since the most of data analysis nowadays is made by different scripts, the loss of scripting capability could seem to be a tremendous blow to framework functionality, but in fact every thing one could do with script, one also can do with declaration and declaration processing rules. Also purely declarative description allows for easy error check and analysis scaling (via parallelism).
Note: Those, who still like scripting, can still either use DataForge as a library, or use GRIND
Automatic scaling. Since particular analysis of some piece of data depends only on that piece and on it's meta-data, such analysis could be easily scaled for any number of such data pieces.
Meta composition. Since the configuration of analysis and meta-data ara both have fixed representation, one could easily combine specific analysis configuration from different parts taken from different sources. For example, one could have a general configuration for the whole data set and specific changes for some specific point. One do not have to write a specific script to work with this particular point, just override its meta-data!
No global state. Since neither data, nor meta-data account for global states, there are no global states! The closest to the global states as you get is context variables (see context), which are used to connect analysis process to system environment, but these states are not used in the analysis itself.
Automatic data flow organisation. Since user does not in general control the order and time of actions performed by the framework, the work of arranging data flow, result caching, etc. could be actually done by the framework itself.

|
The Meta object is a tree-like structure, which can contain other meta objects as branches (which are called elements) and Value objects as leafs. Both Values and Meta elements are organized in String-keyed maps. And each map element is a list of appropriate type. By requesting single Value or Meta element one is supposed to request first element of this list. Note that such lists are always immutable. Trying to change it may cause a error. While meta itself does not have any write methods and is considered to be immutable, some of its extensions do have methods that can change meta structure. One should be careful not to use mutable meta elements when one need immutable one. In order to conveniently edit meta, there is MetaBuilder class. |
The naming of meta elements and values follows basic DataForge naming and navigation convention.
Meaning that elements and values could be called like child_name.grand_child_name.value_name.
One can event use numbers as queries in such paths like child_name.grand_child_name[3].value_name.
An important part of working with meta is composition. Let us work with two use-cases:
- There is a data supplied with meta and one needs modified version of the meta.
- There is a list of data with the same meta and one needs to change meta only for one data piece.
DataForge provides instruments to easily modify meta (or, since meta is immutable, create a modified instance), but it is not a good solution. A much better way is to use instrument called Laminate. Laminate implements meta specification, but stores not one tree of values, but multiple layers of meta. When one requests a Laminate for a value ore meta, it automatically forwards request to the first meta layer. If required node or value is not found in the first layer, the request is forwarded to second layer etc. Laminate also contains meta descriptor, which could be used for default values. Laminate functionality also allows to use information from all of its layers, for example join lists of nodes instead of replacing them. Laminate layers also could be merged together to create classical meta and increase performance. Of course, in this case special features like custom use of all layers is lost.
Using Laminate in case 1 looks like this: if one needs just to change or add some value, one creates a Laminate with initial meta as second layer and override layer containing only values to be changed as first.
For case 2 the solution is even simpler: DataNode structures automatically uses laminates to define meta for specific data pieces. So one needs just to define meta for specific data, it will be automatically layered with node meta (or multiple meta elements if node data node structure has many levels).
The typical usage of data layering could be demonstrated on Actions (push data flow). Action has 3 arguments: Context, DataNode and Meta. The actual configuration for specific Data is defined as a laminate containing data meta layer, node meta layer(s) and action meta layer. Meaning that actual action meta is used only if appropriate positions are not defined in data meta (data knows best about how it should be analyzed).
The configuration is a very important extension of basic Meta class. It is basically a mutable meta which incorporates external observers. It is also important that while simple Meta knows its children knows its children, but could be attached freely to any ancestor, configuration has one designated ancestor that is notified than configuration is changed.
Note that putting elements or values to configuration follows the same naming convention as getting from it.
Meaning putting to some_name.something will actually create or put to the node some_name if it exists.
Otherwise, new node is created.
Meta structure supports so-called hidden values and nodes. These values and nodes exist in the meta and could be requested either by user or framework, but are not shown by casual listing. These values and nodes are considered system and are not intended to be defined by user in most cases.
Hidden values and nodes names starts with symbol @ like @node. Not all meta-data representations allow this symbol so in could be replaced by escaped sequence _at_ in text format (<_at_node/> in XML).
The important part of DataForge architecture is the context encapsulation. One of the major problems hindering parallel applications development is existence of mutable global states and environment variables. One of the possible solutions to this problem is to run any process in its own personal sandbox carrying copies of all required values, another one is to make all environment values immutable. Another problem in modular system is dynamic loading of modules and changing of their states.
In DataForge all these problems are solved by Context object (the idea is inspired by Android platform contexts). Context holds all global states (called context properties), but could in fact be different for different processes. Most of complicated actions require a context as a parameter. Context not only stores values, but also works as a base for plugin system and could be used as a dependency injection base. Context does not store copies of global values and plugins, instead one context could inherit from another. When some code requests value or plugin from the context, the framework checks if this context contains required feature. If it is present, it is returned. If not and context has a parent, then parent will be requested for the same feature.
There is only one context that is allowed not to have parent. It is a singleton called Global. Global inherits its values directly form system environment. It is possible to load plugins directly to Global (in this case they will be available for all active context), though it is discouraged in large projects. Each context has its own unique name used for distinction and logging.
The runtime immutability of context is supported via context locks. Any runtime object could request to lock context and forbid any changes done to the context. After critical runtime actions are done, object can unlock context back. Context supports unlimited number of simultaneous locks, so it won't be mutable until all locking objects would release it. If one needs to change something in the context while it is locked, the only way to do so is to create an unlocked child context (fork it) and work with it.
Plugin system allows to dynamically adjust what modules are used in the specific computation. Plugin is an object that could be loaded into the context. Plugins fully support context inheritance system, meaning that if requested plugin is not found in current context, the request is moved up to parent context. It is possible to store different instances of the same plugin in child and parent context. In this case actual context plugin will be used (some plugins are able to sense the same plugin in the parent context and use it).
Context can provide plugins either by its type (class) or by string tag, consisting of plugin group, name and version (using gradle-like notation <group>:<name>:<version>).
Note: It is possible to have different plugins implementing the same type in the context. In this case request plugin by type becomes ambiguous. Framework will throw an exception if two ore more plugins satisfy plugin resolution criterion in the same context.
A plugin has a mutable state, but is automatically locked alongside with owning context. Plugin resolution by default uses Java SPI tool, but it is possible to implement a plugin repository and use it to load plugins.
Note: While most of modules provide their own plugins, there is no rule that module has strictly one plugin. Some modules could export a number of plugins, while some of them could export none.
Providers
The navigation inside DataForge object hierarchy is done via Provider interface. A provider can give access to one of many targets. A target is a string that designates specific type of provided object (a type in user understanding, not in computer language one). For given target provider resolves a name and returns needed object if it is present (provided).
Names
The name itself could be a plain string or consist of a number of name tokens separated by . symbol. Multiple name tokens are usually used to describe a name inside tree-like structures. Each of name tokens could also have query part enclosed in square brackets: []. The name could look like this:
1
| |
Paths
A target and a name could be combined into single string using path notation: <target>::<name>, where :: is a target separating symbol. If the provided object is provider itself, then one can use chain path notation to access objects provided by it. Chain path consists of path segments separated by / symbol. Each of the segments is a fully qualified path. The resolution of chain path begins with the first segment and moves forward until path is fully resolved. If some path names not provided or the objects themselves are not providers, the resolution fails.

Default targets
In order to simplify paths, providers could define default targets. If not target is provided (either path string does not contain :: or it starts with ::), the default target is used. Also provider can define default chain target, meaning that this target will be used by default in the next path segment.
For example Meta itself is a provider and has two targets: meta and value. The default target for Meta is meta, but default chain target is value, meaning that chain path child.grandchild/key is equivalent of meta::child.grandchild/value::key and will point to the value key of the node child.grandchild.
Note The same result in case of Meta could be achieved by some additional ways:
child/meta:grandchild/keyutilizing the fact that each meta in the hierarchy is provider;value::child.grandchild.keyusing value search syntax.
Still the path child.grandchild/key is the preferred way to access values in meta.
Restrictions and recommendations
Due to chain path notation, there are some restrictions on symbols available in names:
Symbol
/is not allowed in names.Symbols
[]are restricted to queriesSymbol
::allowed in name only if target is explicitly provided. It is strongly discouraged to use it in name.Symbol
.should be used with care when not using tree structures.DataForge uses
UTF-8encoding, so it is possible to use any non-ASCII symbols in names.
Implementation

|
This section is under construction... |
One of the most important features of DataForge framework is the data flow control. Any
Actions
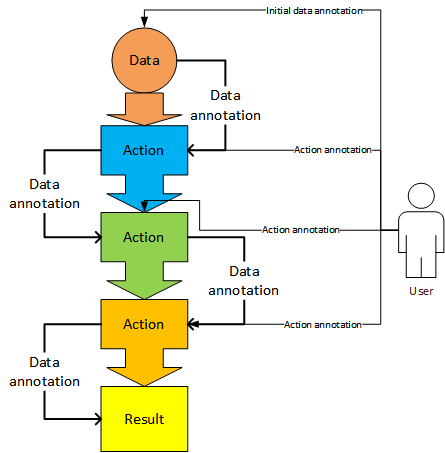
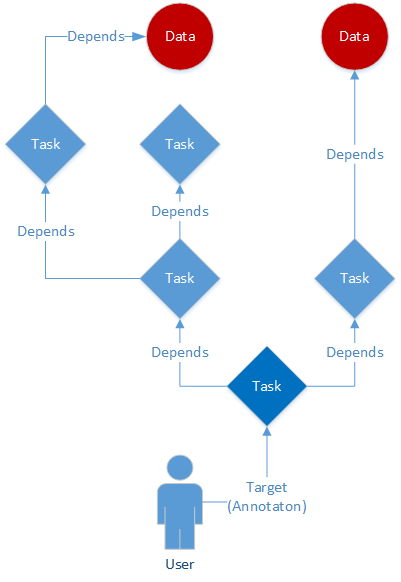 Tasks
Tasks
The DataForge functionality is largely based on metadata exchange and therefore the main medium for messages between different parts of the system is Meta object and its derivatives. But sometimes one needs not only to transfer metadata but some binary or object data as well. For this DataForge supports an 'Envelope' entity, which contains both meta block and binary data block. Envelope could be automatically serialized to or from a byte stream.
DataForge supports an extensible list of Envelope encoding methods. Specific method is defined by so-called encoding properties - the list of key-value pairs that define the specific way the meta and data are encoded. Meta-data itself also could have different encoding. Out of the box DataForge server supports two envelope formats and three meta formats.
The default envelope format is developed for storage of binary data or transferring data via byte stream. The structure of this format is the following:
Tag. First 20 bytes of file or stream is reserved for envelope properties binary representation:
#~- two ASCII symbols, beginning of binary string.- 4 bytes - properties
typefield: envelope format type and version. For default format the stringDF02is used, but in principle other envelope types could use the same format. - 2 bytes - properties
metaTypefield: metadata encoding type. - 4 bytes - properties
metaLengthfield: metadata length in bytes including new lines and other separators. - 4 bytes - properties
dataLengthfield: the data length in bytes. ~#- two ASCII symbols, end of binary string.\r\n- two bytes, new line.
The values are read as binary and transformed into 4-byte unsigned tag codes (Big endian).
Metadata block. Metadata in any accepted format. Additional formats could be provided by modules. The default metadata format is UTF-8 encoded XML (tag code 0x584d). JSON format is provided by storage module.
One must note that
metaLengthproperty is very important and in most cases is mandatory. It could be set to0xffffffffor-1value in order to force envelope reader to derive meta length automatically, but different readers do it in a different ways, so it strongly not recommended to do it if data block is not empty.Data block. Any other data. If
dataLengthproperty is set to0xffffffffor-1, then it is supposed that data block ends with the end of file or stream. It is discouraged to use infinite data length for streaming data. Data block does not have any limitations for its content. It could even contain envelopes inside it!
Meta encoding
DataForge server supports following metadata encoding types:
- XML encoding. The full name for this encoding is
XML, the tag code isXM. - JSON encoding (currently supported only with
storagemodule attached). The full name isJSON, the tag code isJS. - Binary encoding. DataForge own binary meta representation. The full name is
binary, the tag code isBI.
To avoid confusion. All full names are case insensitive. All meta is supposed to always use UTF-8 character encoding.
Tagless format is developed to store textual data without need for binary block at the beginning. It is not recommended to use it for binary data or for streaming. The structure of this format is the following:
The header line.
#~DFTL~#. The line is used only for identify the DataForge envelope. Standard reader is also configured to skip any lines starting with # before this line, so it is compatible with shebang. All header lines in tagless format must have at least new line\ncharacter after them (DOS/Windows new line\r\nis also supported).Properties. Properties are defined in a textual form. Each property is defined in its own lined in a following way:
1#? <property key> : <property value>; <new line>Any whitespaces before
<property value>begin are ignored. The;symbol is optional, but everything after it is ignored. Every property must be on a separate line. The end of line is defined by\ncharacter so both Windows and Linux line endings are valid. Properties are accepted both in their textual representation or tag code.Meta block start. Meta block start string is defined by
metaSeparatorproperty. The default value is#~META~#. Meta block start could be omitted if meta is empty.Meta block. Everything between meta block start and data block start (or end of file) is treated like meta.
metaLengthproperty is ignored. It is not recommended to use binary meta encoding in this format.Data start block. Data block start string is defined by
dataSeparatorproperty. The default value is#~DATA~#. Data block start could be omitted if data is empty.Data block. The data itself. If
dataLengthproperty is defined, then it is used to trim the remaining bytes in the stream or file. Otherwise the end of stream or file is used to define the end of data.
Interpretation of envelope contents is basically left for user, but for convenience purposes there is convention for envelope description encoded inside meta block.
The envelope description is placed into hidden @envelope meta node. The description could contain following values:
@envelope.type(STRING): Type of the envelope content@envelope.dataType(STRING): Type of the envelope data@envelope.description(STRING): Description of the envelope content@envelope.time(TIME): Time of envelope creation
Both envelope type and data type are supposed to be presented in reversed Internet domain name like java packages.
Storage plugin defines an interface between DataForge and different data storage systems such as databases, remote servers or other means to save and load data.
The main object in storage system is called Storage. It represents a connection to some data storing back-end. In terms of SQL databases (which are not used by DataForge by default) it is equivalent of database. Storage could provide different Loaders. A Loader governs direct data pushing and pulling. In terms of SQL it is equivalent of table.
Note: DataForge storage system is designed to be used with experimental data and therfore loaders optimized to put data online and then analyze it. Operations to modify existing data are not supported by basic loaders.
Storage system is hierarchical: each storage could have any number of child storages. So ot is basically a tree. Each child storage has a reference for its parent. The sotrage without a parent is called root storage. The system could support any number of root storages at a time using storage context plugin.
By default DataForge storage module supports following loader types:
- PointLoader. Direct equivalent of SQL table. It can push or pull
DataPointobjects.PointLoadercontains information aboutDataPointDataFormat. It is assumed that this format is just a minimum requirement forDataPointpushing, but implementation can just cut all fields tht are not contained in loader format. - EventLoader. Can push DataForge events.
- StateLoader. The only loader that allows to change data. It holds a set of key-value pairs. Each subsequent push overrides appropriate state.
- BinaryLoader. A named set of
fragmentobjects. Type of these objects is defined by generic and API does not define the format or procedure to read or right these objects.
Loaders as well as Storages implement Responder interface and and could accept requests in form of envelopes.
The FileStorage is the default implementation of storage API.
|
|
This section is under construction... |
DataForge control subsystem defines a general api for data acquisition processes. It could be used to issue commands to devices, read data and communicate with storage system or other devices.
The center of control API is a Device class.
The device has following important features:
- States: each device has a number of states that could be accessed by `getState` method. States could be either stored as some internal variables or calculated on demand. States calculation is synchronous!
- Listeners: some external class which listens device state changes and events. By default listeners are represented by weak references so they could be finalized any time if not used.
- Connections: any external device connectors which are used by device. The difference between listener and connection is that device is obligated to notify all registered listeners about all changes, but connection is used by device at its own discretion. Also usually only one connection is used for each single purpose.
DataForge also supports a number of language extensions inside JVM.
Grind is a thin layer overlay for DataForge framework written in dynamic Java dialect Groovy. Groovy is a great language to write fast dynamic scripts with Java interoperability. Also it is used to work with interactive environments like beaker.
GRIND module contains some basic extensions and operator overloading for DataForge, a DSL for building Meta. Also in separate modules is an interactive console using GroovyShell and some mathematical extensions.
Kotlin is one of the best efforts to make a "better Java". The language is probably not the best way to write a complex architecture like the one used in DataForge, but it definitely should be used in end-user application. KODEX contains some basic DataForge classes extensions as well as operator override for values and metas. It is planned to also include a JavaFX extension library based on the great tornadofx.